<placeholder> - [Description here]
Where all products are supposed to simplify planning and holding a presentation, our product aims to make it more difficult. While planning will be simple, our product intends to provide practice in holding a presentation, improvising, and generally being able to keep calm in front of an audience.
We will be using machine learning in a cloud-based solution to provide a website that will listen to what you say, and based on options and weightings, continuously create a presentation based on what you are talking about.
 Figure: Concept drawing.
Figure: Concept drawing.
The components it will feature:
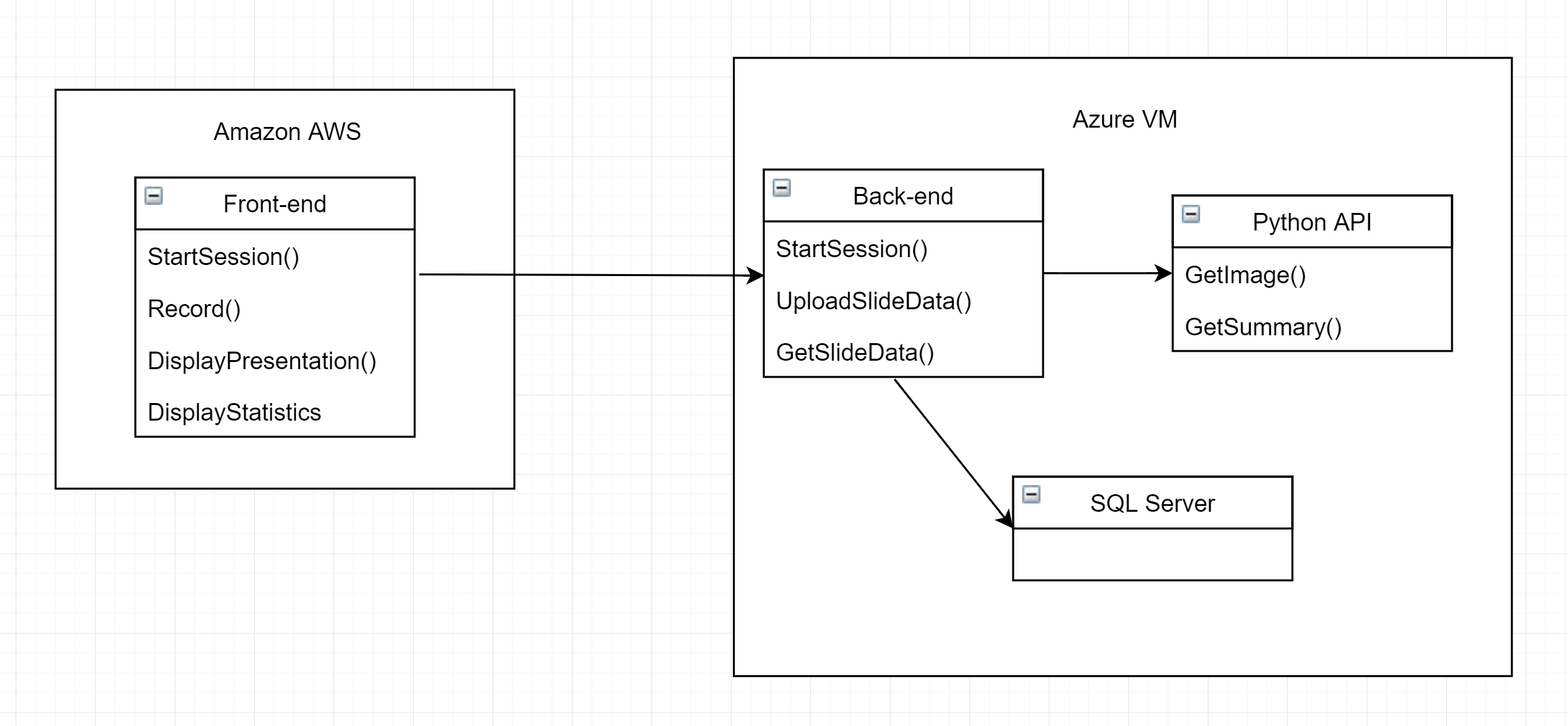
- A front-end website which offers options and such, and, most importantly, records what you say and uses a cloud service to transcribe it to text.
- A back-end to which the front-end sends the transcribed audio as text, handles sessions, and which calls a Python API to retrieve an image based on the latest text.
- a Python API which receives some text, and uses that to retrieve one or more images from Google which will be displayed.
- One or more sensors (pulse meter, accelerometer, etc.) which can be used to measure the calmness of the speaker.
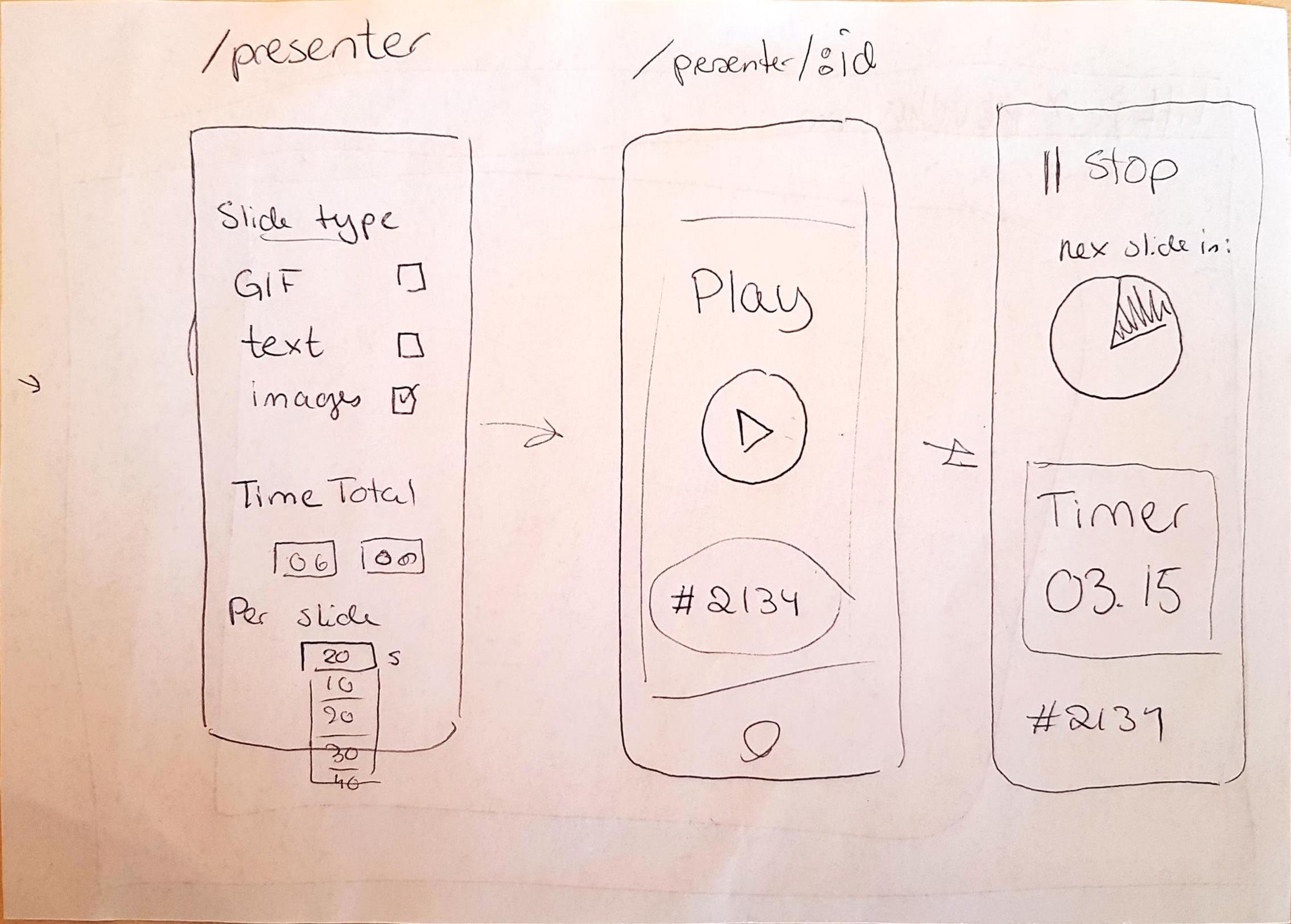 Figure: In one scenario the microphone will be captured through the browser on the presenters phone. The presenter will then also be able to select the type of presentation and other options.
Figure: In one scenario the microphone will be captured through the browser on the presenters phone. The presenter will then also be able to select the type of presentation and other options.
The data flow:
- The front-end asks the back-end to start a new session, and receives a session ID.
- Front-end records audio, transcribes it, and sends it to the back-end with the corresponding session ID.
- The back-end sends the transcribed text to the Python-API.
- The Python API selects what to search for (based on weightings) and retrieves an image from Google image search, then sends the URL to the back-end.
- The presentation page on the front-end (a separate URL) calls the back-end regularly to retrieve the latest image.
Interleaved with this, we intend to have sensors measure the calmness of the presentation holder by checking the pulse, using an accelerometer to see how much the person is walking around and gesticulating, finding words per minute, and more. These sensors will either be obtained through the presenters smart phone or throug a separate hardware similar to a presenters' "clicker", based on WiFi or Bluetooth connected hardware.